Setting up API Gateway
- Kim Rasmussen
- Kim Rasmussen (Unlicensed)
- Patrick Ahmed (Unlicensed)
- Kim Rasmussen (Unlicensed)
Serving APIs
The Ceptor Gateway has API Gateway functionality on top of all its existing capabilities.
Please read the Gateway Concepts for an overview of its capabilities in general and refer to Gateway Configuration for full details.
When serving APIs, you need to create a Location (see Config - Locations for details) that has its action set to serve APIs.
Let's take an example:
Go to the Gateway Configuration in the menu, and add a new location:
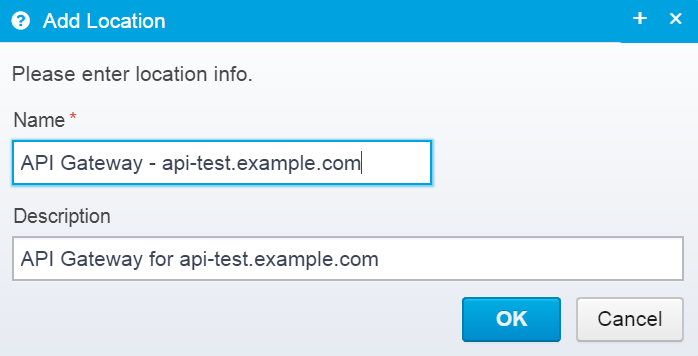
Place it near the top in the gateway list, and save it.
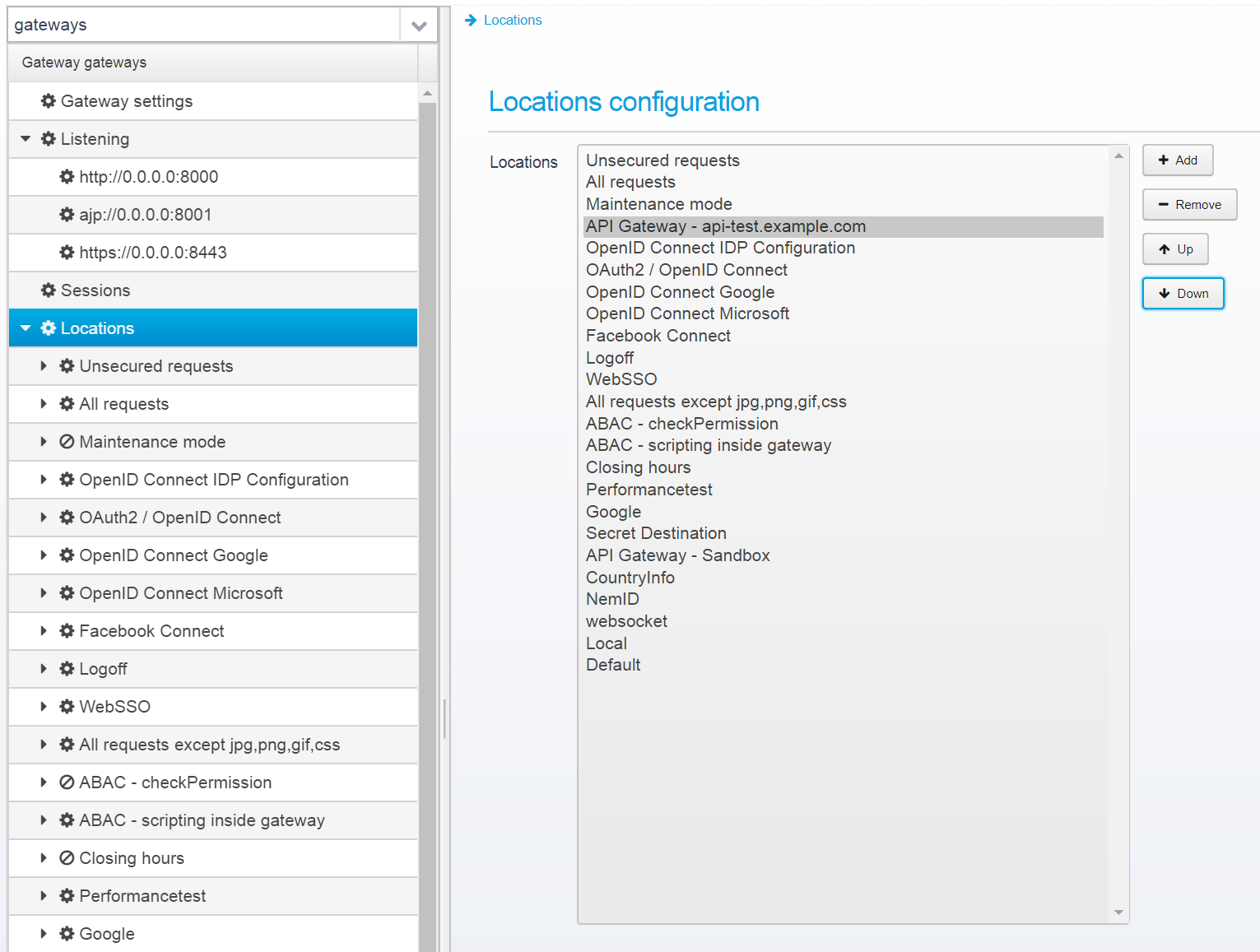
Now, you can go to the locations configuration and change its settings.
Add a condition for when this Location will be called, e.g. if the hostname is api-test.example.com
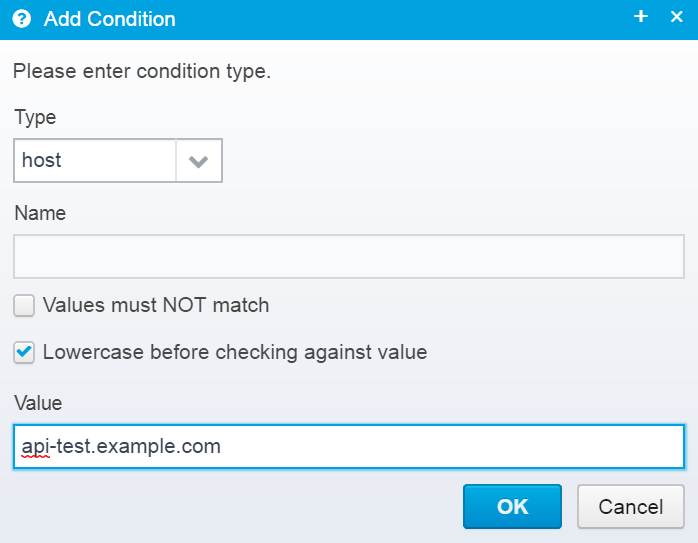
You can add any other conditions you wish to limit when this location will be triggered.
Go to the location settings, set the "Valid HTTP Methods" to "*" or whichever set of HTTP methods you want to limit it to.
Set the Action to serveapi which is what enables the API Gateway functionality for this location.
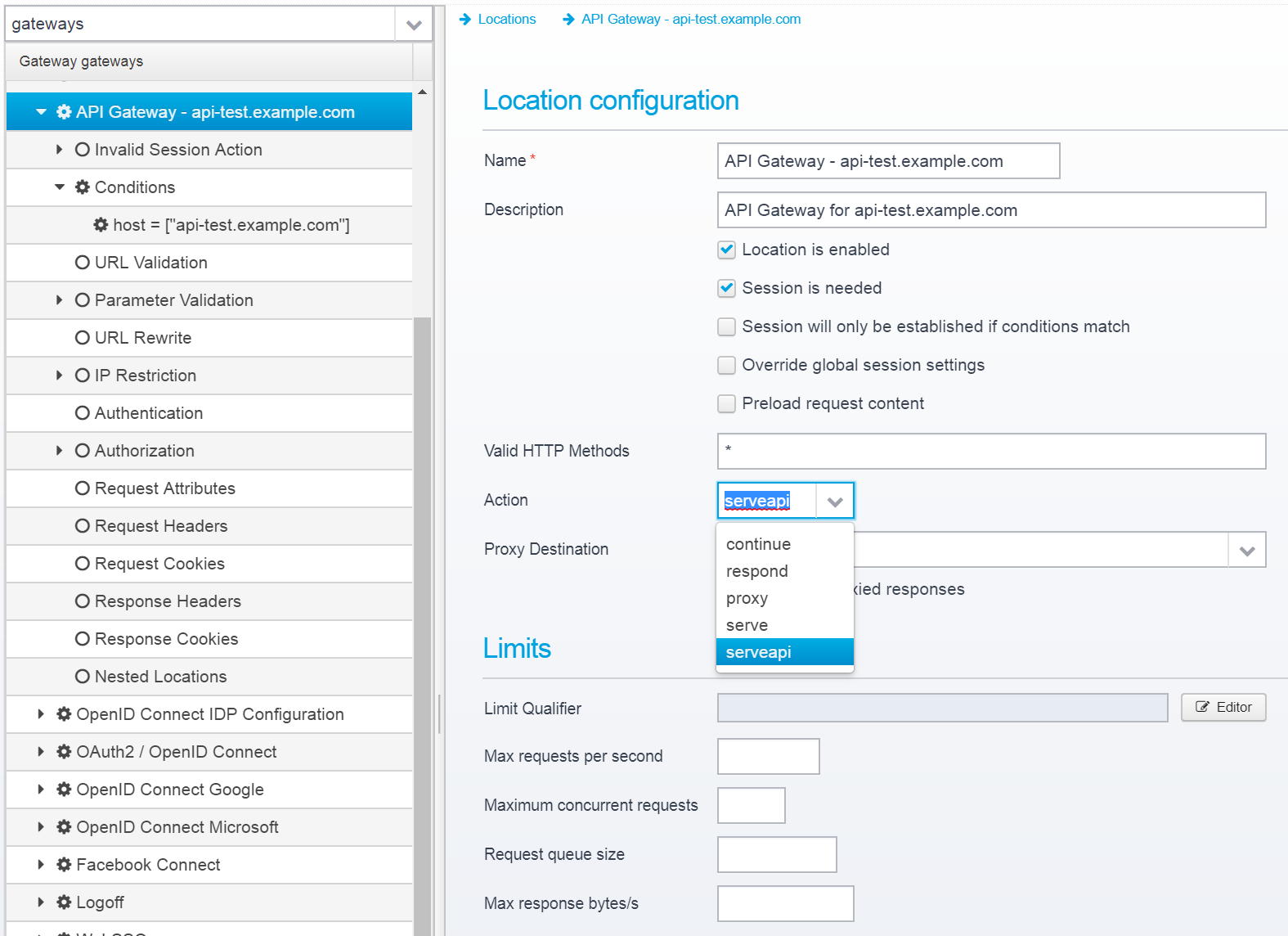
Now, save it.
After saving, you will notice that there is a new section available; "API Gateway" - go there to configure the remaining settings:
Select the environment you want to serve APIs for, choose a Rate Limiter and add any API Usage reporters you wish. You can also change the interval between remote API specification reloads (a functionality of a particular API Version where the OpenAPI specification is not stored locally, but retrieved from remote - e.g. when generated using Spring Boot or other frameworks).
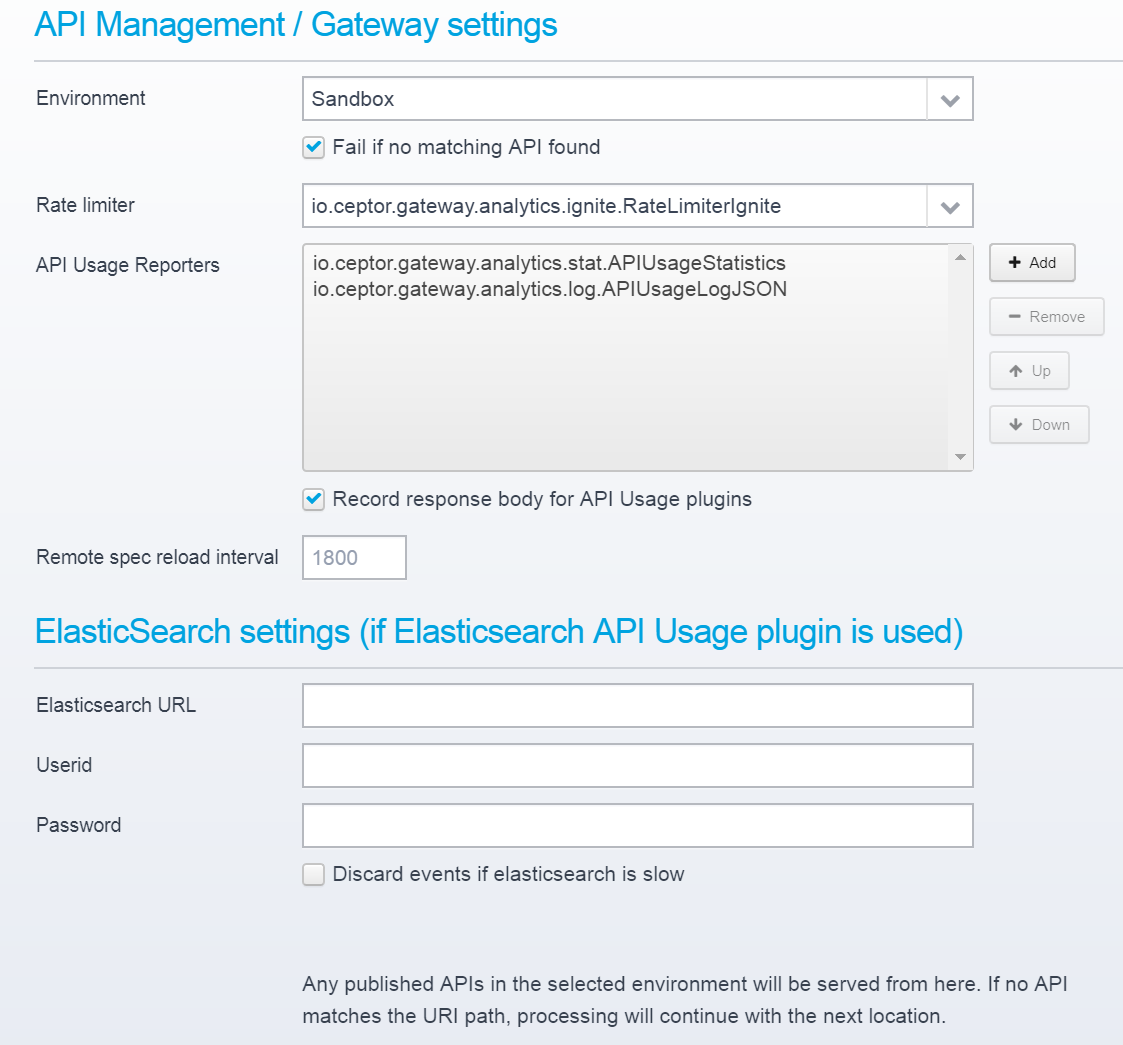
Rate Limiter
A rate limiter implementation decides how rate limits are implemented for this location - it is possible to add your own custom rate limiting implementation which you can use, or you can choose one of the defaults.
If no rate limiters are set up, rate limiting (set up on Subscription Plans and Rate Limit Groups) will be ignored.
By default, Ceptor comes with support for these implementations:
- io.ceptor.gateway.analytics.ignite.RateLimiterIgnite
This implementation uses an Apache Ignite Cluster to store rate limits in - the rate limits are persisted within the cluster, so this will offer you the best option at the cost of a slight performance decrease in persisting the information. This performance hit will be 1-2 milliseconds in most setups, but is still measurable.
If exact rate limits is a priority, you should choose this implementation. - io.ceptor.gateway.analytics.memory.RateLimiterMemory
This implementation stores information in-memory - it is not replicated between gateways, so each gateway within a cluster has its own information stored.
This has virtually no performance overhead, but has the disadvantage that it is not exact - since information is stored locally for each gateway in a cluster, and since it will be lost if the process is restarted.
But, it is the fastest implementation available so you can choose this if accuracy is not a large concern, if you have relatively short-lived limitations configured, and if performance is most important. - io.ceptor.gateway.analytics.sql.RateLimiterSQL
This implementation of a Rate Limiter uses SQL/JDBC towards a shared database - rate limits are persisted in the database and shared between instances - depending on the database used, there is an overhead - e.g. in Apache Derby, the overhead is ~1 millisecond, so comparable to Apache Ignite, but offering a simpler setup.
Only a single implementation can be used at a time for a given location.
API Usage Reporters
An API Usage plugin reports API usage per call - it stores information about who made the call, when it was made, its response time etc. An API Usage plugin is invoked after the call has completed, and has access to all the information also available for access logging.
You can create your own custom implementations, or use one of the default ones.
If no API Usage reporters are setup, no specific API usage will be reported, and just the regular access log will be used instead.
By default, Ceptor comes with support for these implementations:
io.ceptor.gateway.analytics.log.APIUsageLog
This API Usage plugin simply logs the call in the regular log using SLF4J which can then be redirected to a specific destination using regular log configuration. It uses the logger name "apiusage".
Below, is the entire implementation, so you can see exactly what information is logged.public class APIUsageLog implements IAPIUsage { private Logger log = LoggerFactory.getLogger("apiusage"); @Override public void reportUsage(StateHolder state, APIVersion apiVersion, Operation operation) { StringBuilder sb = new StringBuilder(); if (state.apiPartner == null || state.apiPartnerApplication == null) { try { if (state.id != null && state.agent.isLoggedOn(state.id)) { sb.append("Anonymous call to APIVersion ID: [").append(apiVersion.id); sb.append("], API Name: [").append(apiVersion.prettyName); sb.append("]"); } else { sb.append("Anonymous call to APIVersion ID: [").append(apiVersion.id); sb.append("], API Name: [").append(apiVersion.prettyName); sb.append("]"); } } catch (PTException e) { // Ignore if connection is broken. } } else { sb.append("API Partner - ID: [").append(state.apiPartner.id); sb.append("], Name: [").append(state.apiPartner.name); sb.append("], App ID: [").append(state.apiPartnerApplication.id); sb.append("], App name: [").append(state.apiPartnerApplication.name); sb.append("] called APIVersion ID: [").append(apiVersion.id); sb.append("], API Name: [").append(apiVersion.prettyName); sb.append("]"); } log.info(sb.toString()); } }io.ceptor.gateway.analytics.stat.APIUsageStatistics
This API Usage plugin stores information about the call in Ceptor's Statistics (see Statistics and Ceptor Statistics Server for details).
Below, you can see exactly what data is available in the statistics:public void reportUsage(StateHolder state, APIVersion apiVersion, Operation operation) { StringBuilder sb = new StringBuilder(); sb.append("Call to API [").append(apiVersion.id).append("] - [").append(apiVersion.prettyName); sb.append("] from "); if (state.apiPartner == null || state.apiPartnerApplication == null) { try { if (state.id != null && state.agent.isLoggedOn(state.id)) { sb.append("user: [").append(state.agent.getUser(state.id)).append("]"); } else { sb.append("anonymous"); } } catch (PTException e) { // Ignore if we cannot see if user is logged in. } } else { sb.append("API Partner - ID: [").append(state.apiPartner.id); sb.append("] Name: [").append(state.apiPartner.name); sb.append("] App ID: [").append(state.apiPartnerApplication.id).append("]"); } long requestStartTime = state.httpExchange.getRequestStartTime(); if (requestStartTime == -1) { state.agent.measureStatistics(sb.toString(), 0); } else { long nanos = System.nanoTime() - requestStartTime; state.agent.measureStatistics(sb.toString(), TimeUnit.MILLISECONDS.convert(nanos, TimeUnit.NANOSECONDS)); } }io.ceptor.gateway.analytics.stat.APIUsageElasticSearch
This API Usage plugin stores information about the API Call in Elasticsearch - allowing storing full detail and allowing extensive data-mining on API calls to be made.
The following information is stored in Elasticsearch:{ "apiversion.id": apiVersion.id, "api.id": apiVersion.apiId, "prettyname": apiVersion.prettyName, "sessionid": state.id, // If API Partner information is available, meaning API requires subscription or API partner was logged on using another method "apipartner.id", state.apiPartner.id, "apipartner.name", state.apiPartner.name, "apipartner.application.id", state.apiPartnerApplication.id, "apipartner.application.name", state.apiPartnerApplication.name, // If API Partner information is NOT available, but the user is logged on using other means "user", state.agent.getUser(state.id), // This information is always available "remote.ip", state.gateway.getClientSourceIP(state), "remote.port", state.gateway.getClientSourcePort(state), "request.method", state.httpExchange.getRequestMethod().toString(), "request.path", state.httpExchange.getRequestPath(), "request.host", state.httpExchange.getHostAndPort(), "request.query", state.httpExchange.getQueryString(), "request.headers", all request headers and values. "request.body", HTTP Request body if request is textual "request.body.base64", HTTP Request body if request is binary "response.status", state.httpExchange.getStatusCode(), "response.bytes", state.httpExchange.getResponseBytesSent(), "response.time", response_time_in_milliseconds, "response.endtime.msecs", System.currentTimeMillis(), "response.headers", all response headers and values. "response.body", HTTP Request body if response is textual "response.body.base64", HTTP Response body if response is binary - note that this might need to be unzipped if response content-encoding was gzip. // The exception is only present if the call failed "exception", "exception string and stacktrace" }io.ceptor.gateway.analytics.log.APIUsageLogJSON
Like when using io.ceptor.gateway.analytics.log.APIUsageLog - this plugin records API Usage information to the log, but instead of logging a text message, it logs a JSON message with the same content as the one used by the ElasticSearch API Usage log plugin. This enables you to use SLF4J/Logback appender to redirect the logging to any appropriate place, such as a database, syslog or any other destination supported by a standard Logback appender.
This API Usage plugin uses the logger name "apiusage" when logging messages.
Note that multiple API Usage plugins can be configured at a time, so you can store API Usage information e.g. both in the logs, and in elasticsearch.
This is an example of the JSON created by the standard API Usage plugin:
{
"apiversion.id": "a34a268f-34b1-465c-9327-262c2c69c4d3",
"api.id": "3fe3ac57-c2da-4ce2-a2bc-25202f62c88b",
"prettyname": "Hello World (Demonstration APIs) 1",
"sessionid": "CEPID_AA8BMDowOjA6MDowOjA6MDoxACwCAAABZgeZf-AAAAANS03BgL8QbYIh6e-qCwKtlM9CTkIWwb1OoiDBzYW04fEAAQMB~AAIBMDIADwMwOjA6MDowOjA6MDowOjEAAgSQPQAMBTdGODAAAAAAAAABhQ",
"apipartner.id": "25df072a-f500-45a9-83eb-5f99c152b5fb",
"apipartner.name": "Ceptor ApS",
"apipartner.application.id": "45bc3a53-7308-47e7-887a-21cf75cfe404",
"apipartner.application.name": "Test App 1",
"remote.ip": "0:0:0:0:0:0:0:1",
"remote.port": 36925,
"request.method": "GET",
"request.path": "/hello/v1/hello",
"request.host": "localhost:8443",
"request.query": "",
"request.headers": {
"accept": "application/json",
"Accept-Language": "da-DK,da;q=0.9,en-US;q=0.8,en;q=0.7",
"Accept-Encoding": "gzip, deflate, br",
"Origin": "https://localhost:4243",
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36",
"Connection": "keep-alive",
"Authorization": "Basic dGVzdDpzZWNyZXQ=",
"Referer": "https://localhost:4243/",
"Host": "localhost:8443"
},
"response.status": 200,
"response.bytes": 37,
"response.time": 52,
"response.endtime.msecs": 1537725792274,
"response.headers": {
"Access-Control-Allow-Headers": "origin, accept, content-type, authorization, content-length, ceptor-apikey",
"X-XSS-Protection": "1; mode=block",
"Date": "Sun, 23 Sep 2018 18:03:12 GMT",
"Connection": "keep-alive",
"X-RateLimit-Remaining": "2",
"Strict-Transport-Security": "max-age=31536000; includeSubDomains",
"X-RateLimit-Limit": "5",
"Access-Control-Allow-Methods": "GET, POST, PUT, PATCH, DELETE, HEAD, OPTIONS, TRACE",
"X-RateLimit-Reset": "1537725840",
"X-Frame-Options": "sameorigin",
"Via": "1.1 gateway1 (Ceptor/6.0.3)",
"Access-Control-Allow-Origin": "https://localhost:4243",
"X-Content-Type-Options": "nosniff",
"Content-Type": "application/json",
"Content-Length": "37",
"X-RateLimit-Timeunit": "minute",
"Access-Control-Max-Age": "120"
},
"response.body": "{\"text\":\"How nice of you to call me\"}"
}
Record response body for API Usage plugins
If checked, responses will be recorded as they are streamed back, and are available for API Usage plugins for logging.
Default value: false
JSON Key: record.responses
Remote spec reload interval
Defines the number of seconds between reloading remote OpenAPI Specs from backend servers.
Default value: 1800
JSON Key: api.remoteloadinterval.seconds
ElasticSearch Settings
When using elasticsearch to store the statistics within, you need to configure the URL and any eventual userid/password that should be used when saving statistics within it.
Note that elasticsearch can be relatively slow in some environments, so Ceptor updates it asynchronously and can queue up to 10000 requests per gateway. If your API request load exceeds elasticssearch's ability to store events fast enough, you can choose either to discard them (for optimal performance) - or to switch to synchronously storing them. If discarding events is not allowed, Ceptor will instead of sending them asynchronously switch to doing it synchronously.
Note that you will usually need very heavy sustained load of tens of thousands of API calls per second on your system for this to become a problem.
This will block Ceptor API Gateway's threads for some additional milliseconds until elasticsearch responds, and will cause delay in responding to API calls, but it will also ensure that events are not lost even if your elasticsearch cluster is not fast enough to sustain the rate of calls.
Environments & Locations
As you can see above, you configure a Location, and serve APIs from it - there is nothing the prevents you from serving API calls to the same environment from multiple locations, so you can indeed create as many locations as you wish distributed over as many gateway clusters you need and serve the same APIs in the same locations over these.
Adding Additional Security
You can use the full capabilities of the Ceptor Gateway to secure your API calls - any authentication settings you configure in your API security per API version can be overwritten within a Location by creating other authentication settings and override it. If settings for your Location authenticates a user, when the API is called the API Gateway will detect that the user is already authenticated, so it will not attempt to re-authenticate him again.
This allows you to add all sort of exotic requirements, e.g. protect your all your API calls for a particular Location / Environment by Kerberos authentication, allowing you full flexibility to either specify security authentication/authorization restrictions centrally for an environment or for each API.
If you need the OpenAPI API specification to reflect the configured security settings, e.g. OAuth2 URLs, you should configured security on the API Version level.
© Ceptor ApS. All Rights Reserved.